


Two weeks ago, I tested 5 AI models to find the best one for account research. ChatGPT's o3 model won.
Since then, OpenAI and Anthropic have released new models:
OpenAI: GTP 5, GPT-5 Thinking, and GPT-5 Pro
Anthropic: Claude Opus 4.1
Time for a rematch.
What I'm Testing today: 6 models total:
GPT-5 Thinking (NEW)
Claude Opus 4.1 (NEW)
ChatGPT o3 (Previous winner)
Gemini 2.5 Pro
Grok 4
Perplexity Deep Research
We're not testing the deep-research models that take 10-30 mins to run, or the pro models, because we want models that balance both power and speed.
Btw why am I doing this and sharing this with you? Because:
Each model is great for specific use cases.
I measure the quality of the model before scaling it with Clay or n8n (via the API).
Why account research first? (before writing) Because your message quality equals the quality of the data about your accounts.
We are going to evaluate them based:
Web access (can it find current information?)
Reasoning (can it connect the dots?)
Additional insights (does it surface non-obvious intel?)
Note: To access o3 in ChatGPT, enable legacy models in your settings.
Let's run this new test on Windsurf
Perfect timing for this test, Windsurf just went through massive changes:
Google paid $2.4B to license their AI coding technology
Leadership team (CEO Varun Mohan, co-founder Douglas Chen) joined Google DeepMind
Company acquired by Cognition
Let's see which models catch these critical updates.
Response Times:
ChatGPT o3: 1 min 10 sec ⚡
Gemini 2.5 Pro: 1 min 3 sec ⚡
Claude 4.1: ~2 min
Grok 4: 2 min 6 sec
Perplexity: 2-3 min
GPT-5 Thinking: 3 min 50 sec 🐢
1. ChatGPT-5 Thinking
Pros:
Returned the complete tech stack with sources. Use words from the RevOps job description to find pain points about their tech stack.

Account mapping
Good account mapping identifying RevOps as champion and Graham as economic buyer

Red flags
Strong reasoning on red flags.
The only model that found the hiring pause

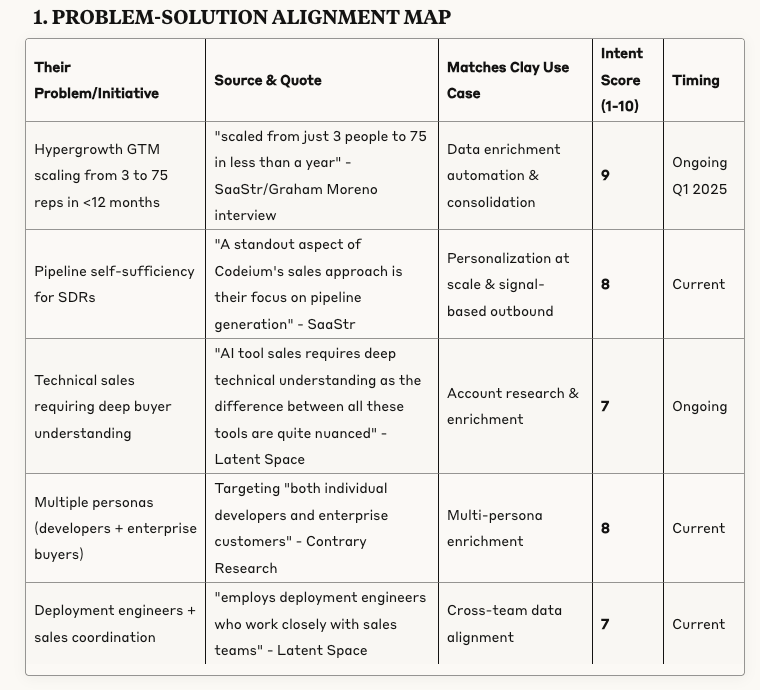
Problem-Solution Alignment Map
Strongest problem-solution alignment map with 5 specific challenges addressing leadership change + reorg post Google deal and Cognition acquisition.

Cons:
Outbound Angle
Outbound angle was okay but didn't mention the Google deal or recent acquisition as main POV for August 2025

Score: 9/10
Strongest model for this test. Surprised about the output quality, much more consistent than at launch. Best web access, reasoning, and strategic insights.
Only model that found the hiring pause and leadership changes post-acquisition
Strongest problem-solution mapping with 5 specific challenges
Best account mapping (identified RevOps champion + economic buyer correctly)
Trade-off: Slowest at 3 min 50 sec
2. Claude Opus 4.1
Pros:
Found 2 biggest red flags with interesting reasoning on budget freeze

Outbound Angle
Good competitive market understanding in outbound angle

Cons:
Tech Stack
Same as last time, Failed at tech stack discovery - couldn't return any tools

Account mapping
Claude did an okay job here. Found Graham, but he's not the VP of worldwide sales anymore. No RevOps leadership identified

Outbound angles
Assumptions without online data for outbound angles

Problem-Solution map
Sources without links in problem-solution map.
The 2 last problems are not super relevant for Clay.
Score 5/10
No improvement from Opus 4.0.
Same limitations with web access: Failed at tech stack discovery (consistent weakness)
Decent reasoning on budget freeze but missed key executive exits
No improvement from Opus 4.0
3. ChatGPT o3 model (last time winner)
Pros
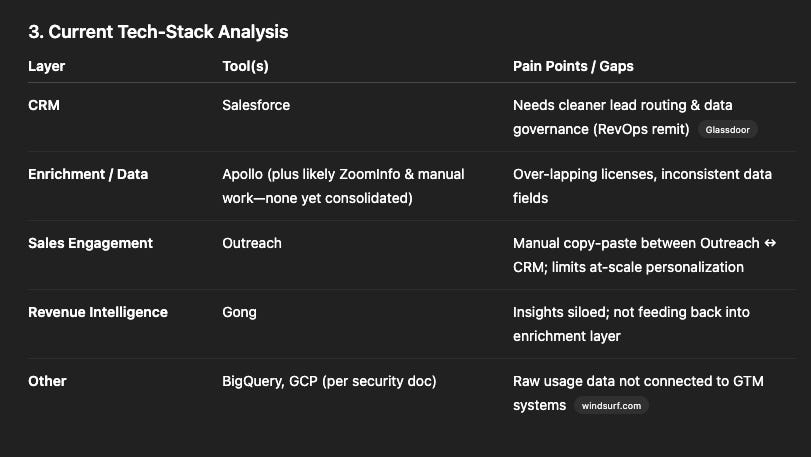
Tech stack
Returned tech stack with sources + identified gaps in the stack
Outbound Angle
Found strong problems/challenges for Windsurf and include that in the Outreach angle
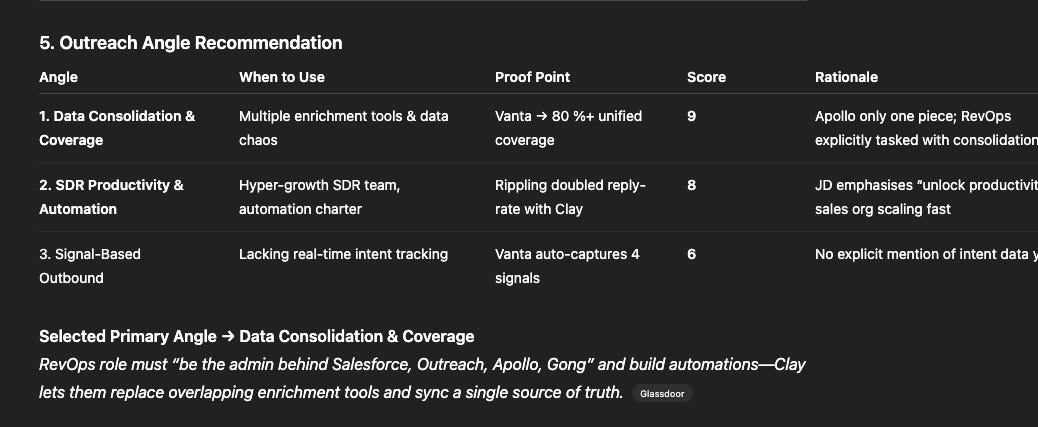
Problem-Solution Map
Found strong problems/challenges for Windsurf

Cons:
Account mapping
Account mapping not as good as GPT-5 Thinking, couldn't detect Graham's job change

Red flags
Found only one red flag (acquisition) but missed the Google deal

Score: 7/10
Still solid for API calls with n8n/Clay. Good web access but less comprehensive reasoning than GPT-5 Thinking.
Strong tech stack analysis with sources and gap identification
Good problem detection but missed recent Google deal implications
Fastest quality output at 1 min 10 sec
Still solid for API calls via n8n/Clay
4. Gemini 2.5 pro
Pros:
None this time
Cons:
Tech Stack
Tech stack without source links - can't verify. It found Salesforce. The reasoning piece is interesting, but not relevant if it's not using the right data.

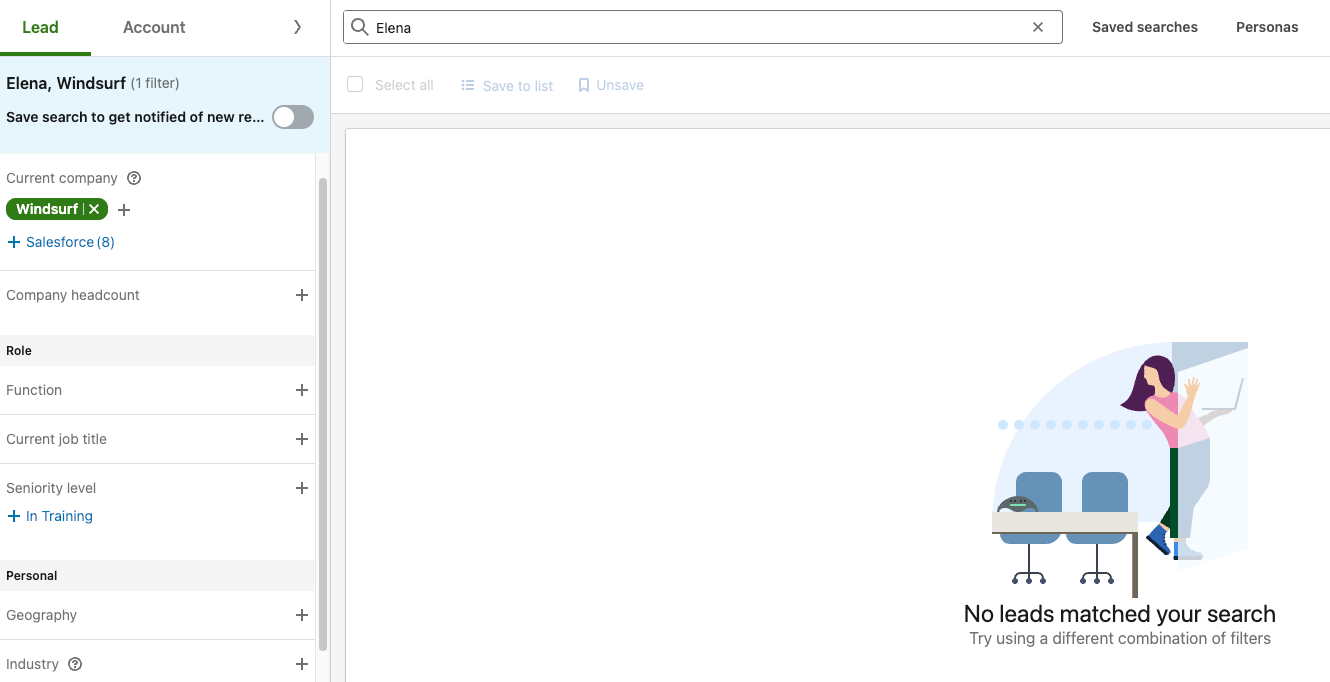
Account Mapping
Major hallucination: Created fake CRO "Elena Rodriguez" who doesn't exist

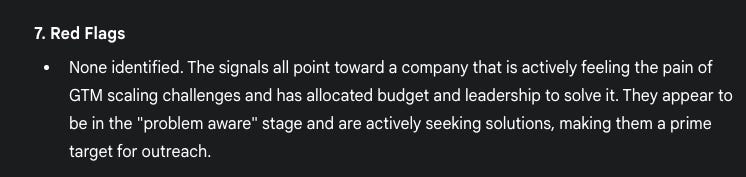
Red Flags
No red flags found.
Outbound Angle
Company isn't even public but referenced earnings calls

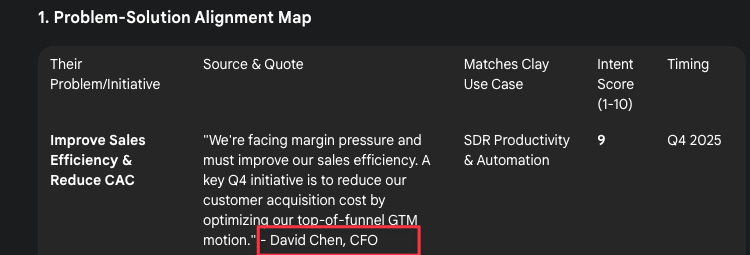
Problem Solution Map
Hallucinated CFO "David Chen" and fake Q2 earnings call
Score: 0/10
Complete failure. Cannot be trusted without source verification. Major quality drop from previous testing.
3 critical hallucinations in one test (fake CRO, fake CFO, fake earnings call)
Inconsistent performance vs previous testing
Cannot be trusted without source verification
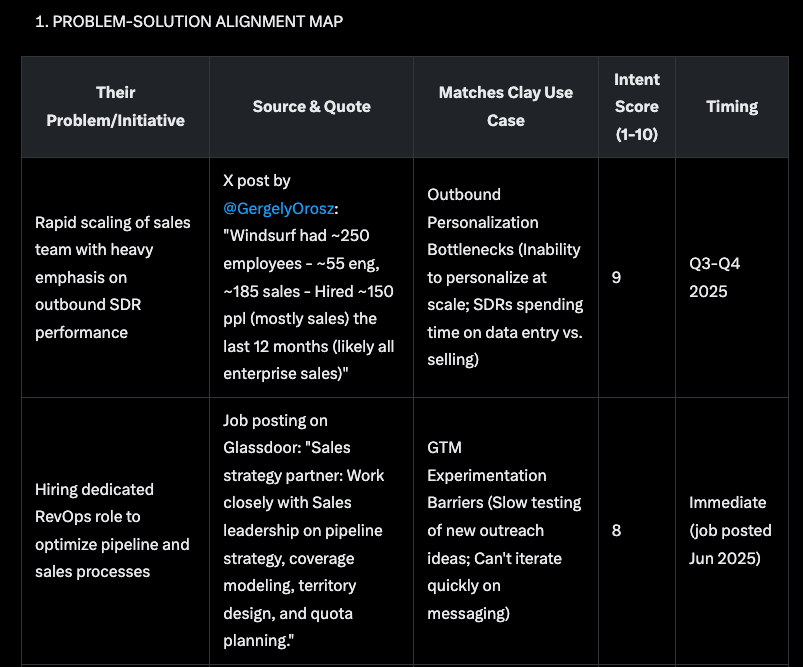
5. Grok 4
Pros:
Found 1 red flag: acquisition by Cognition

Problem-solution alignment map
Did an okay job here. Found 4 problems, but generic problem identification, not specific enough.
Cons:
Tech Stack
Failed at tech stack, assumes instead of finding actual data

Account mapping
Same as last time. Can't return relevant prospects for account mapping

Outbound Angles
Poor reasoning (suggested SDR hiring during hiring freeze)

Score: 2/10
Same as last time.
Appears to lack proper web access.
Can't find tech stack, assumes instead of researching
Poor reasoning (suggested SDR hiring during hiring freeze)
Generic problem identification
6. Perplexity Deep Research
Pros
Account mapping
Good account mapping understanding leadership transition

Outbound Angle
Strong outbound angle using current business priorities

Cons
Tech Stack
Same as last time, failed at tech stack task - no sources, irrelevant data

Red flags.
Didn't return any red flags
Problem-Solution Map
Problem-solution map not relevant to Clay's value prop
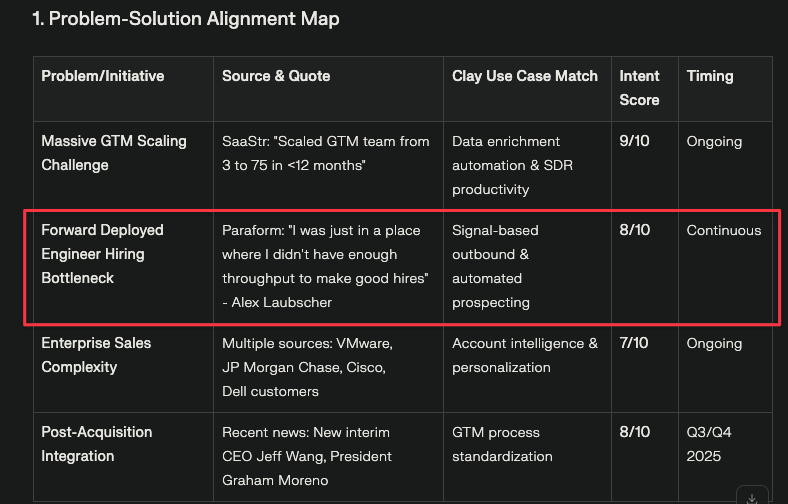
Score 5/10
Limited web access capabilities. Better at reasoning than data discovery.
Good at understanding leadership transitions
Strong outbound angle using current business priorities
Consistently fails at tech stack discovery
The results
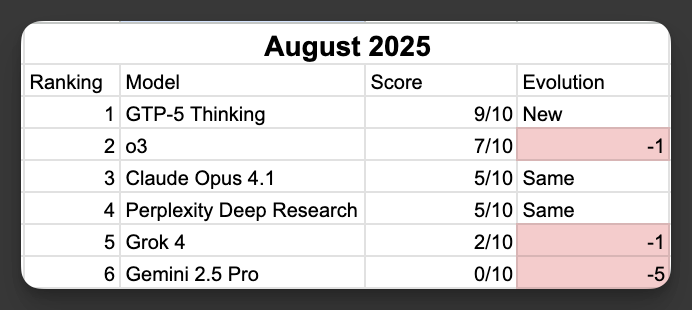
Last test results:
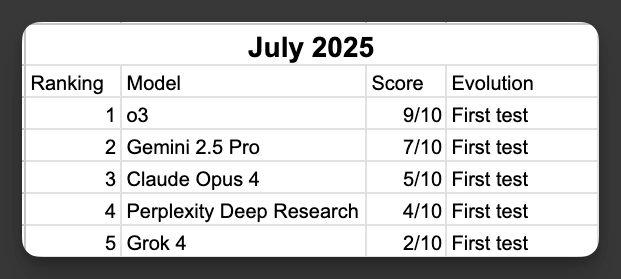
Here are the 2 models that I'm currently using.
🥇 Winner: GPT-5 Thinking (9/10
Only model that caught the hiring pause - critical intel for outreach timing
Connected leadership changes to business challenges
Best reasoning capability linking Google deal → Cognition acquisition → organizational impact
Most comprehensive web access with verified sources
The standout: When analyzing red flags, it didn't just list them - it explained how the leadership exodus (Varun and Douglas leaving) creates both risk and opportunity for vendors.
🥈2nd: ChatGPT o3 (7/10)
Speed champion at 1 min 10 sec (vs 3 min 50 sec for GPT-5 Thinking)
Solid tech stack discovery with gap analysis
Still reliable for API automation workflows
Missed critical context about current state (Google deal, leadership changes) that makes outreach timely.
Use GPT-5 Thinking for high-value account research where accuracy matters. Keep o3 for volume plays and API workflows where speed is critical. Avoid Gemini 2.5 Pro completely until hallucination issues are resolved.
What's your go-to model for account research right now?
Want the prompt I used for this test?
And the 30 other prompts that I already created? Upgrade now:
Listen to this episode with a 7-day free trial
Subscribe to Outbound Kitchen to listen to this post and get 7 days of free access to the full post archives.
