


Welcome to a new 🔒 subscriber-only edition 🔒 of my weekly newsletter of Outbound Kitchen. Each week, I dive into reader questions about scaling outbound and making it your #1 growth engine. For more: Launching Outbound, and Scaling Outbound
By the way, if you’d rather watch or listen to this newsletter, you can find it on YouTube, Spotify, Snipd or Apple Podcasts.
Six months ago, I tested 6 AI models for account research.
GPT-5 Thinking took the crown.
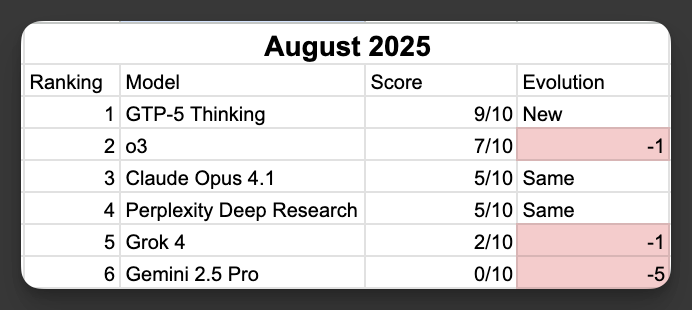
Since then, the landscape has shifted again:
OpenAI: ChatGPT 5.2 Thinking
Anthropic: Claude Opus 4.6
Google: Gemini 3 Pro
xAI: Grok 4.2 (Beta)
Time for round 3.
What I’m testing today: 7 models:
ChatGPT 5.2 Thinking (NEW)
Claude Opus 4.6 (NEW)
Gemini 3 Pro (NEW - The 2.5 model hallucinated last time)
Grok 4.2 Beta (NEW)
Perplexity Sonar Deep Research (returning)
Grok 4 (returning)
Argon by Clay (NEW - first time testing a Clay-native model)
Why I keep doing this:
Two things keep changing: new models are released, and existing models keep improving. The best tool for account research six months ago might not be the best one today. I don’t assume, I test.
Each model is great for specific use cases.
I test the model before I scale it with Clay, Cargo or n8n.
Account research is where model quality matters most. Your message quality and discovery call prep depend on the quality of your research.
1. Today’s Test: TrackRec + Replit
TrackRek:
Today I’m testing this for a company called TrackRec. They help companies hire sales talent faster, verifies quota attainment, ranks candidates on data, cuts time-to-hire.
If you’re a rep at TrackRec, you need to know: Is this company hiring salespeople? Who’s the decision-maker? What’s their employer brand? What tools are they using? Is there a reason to reach out right now?
Replit:
The company I’m testing on: Replit. $2.8M revenue to $150M+ ARR. $250M raise in September. 10+ open sales roles. CRO was on a podcast talking about hiring through his network.
I gave all 7 models the same prompt. 12 specific instructions. Same company, same prompt. Here’s what they found.
Disclaimer
These are my results. One company, one prompt, one test. Your results might be different. The point isn’t “use Perplexity.” The point is: here’s a framework for testing which model works best for YOUR account research.
Important
All models were tested in the web app, except Argon which was tested directly in Clay. Web app vs API vs Clay will give different results, different token limits, different output formats. Next time I will add API testing to the benchmark.ons.
2. What I Changed vs the last test
Last time: 3 criteria (web access, reasoning, additional insights).
This time: 6 weighted categories. Added Accuracy, Business Relevance, and Research Usability. Business Relevance asks: did it find what the BUYER needs? Research Usability: can a rep actually act on this?
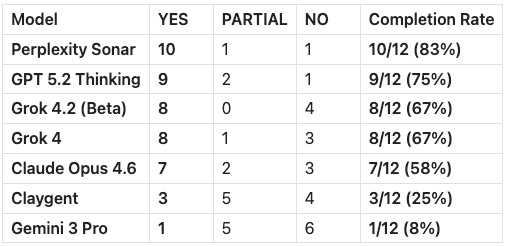
Added an instruction completion table.
The prompt asks 12 specific things. Did you do what I asked? Yes or no. Perplexity did 10/12. Gemini did 1/12.
3. The Scores: Top 3 Deep, Bottom 4 Compressed
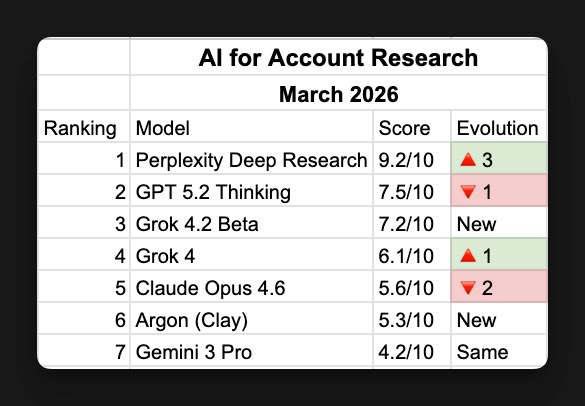
1. Perplexity Sonar — 9.2/10
Found the most. VP of SDR no one else found. Found both funding rounds. Found the CRO’s podcast and pulled quotes from it. One false claim: said RepVue had no profile when 5 other models found it. Best researcher, with one blind spot.



2. GPT 5.2 Thinking — 7.5/10
Zero false claims. 24 citations. Everything it said was true. But missed the January funding round, missed the podcast, missed 7 of 10 tech stack tools. Nothing wrong, but nothing unique. The safest model. Not the deepest.

3. Grok 4.2 Beta — 7.2/10
Fastest model, 56 seconds. Best RepVue depth, found sub-ratings no one else pulled. Honest about uncertainty, hedged on the $400M round instead of stating it as fact. But only found 1 tech stack tool.


Scoreboard (March 2026)

Bottom 4
Grok 4 (6.1/10) — Found the $400M round but generic reasoning. Reliable, not insightful.
Claude Opus 4.6 (5.6/10) — Best reasoning in the test. Worst champion identification. Missed the CRO despite checking 11 sources. Use for analysis, not finding people.
Argon (Clay) (5.3/10) — Found the CRO and the podcast from just 4 pages. Most efficient model. But too thin for standalone research.
Gemini 3 Pro (4.2/10) — Worst researcher. 1/12 instructions completed.
4. What I Found When I Verified Everything
After scoring, I manually verified every claim the models disagreed on. Six disputed facts. Checked LinkedIn, the articles, Replit’s website.
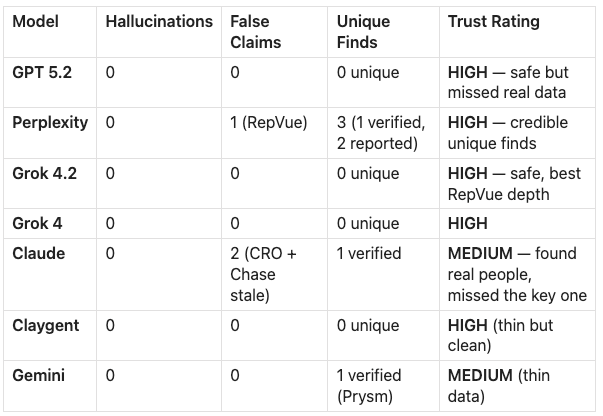
Zero hallucinations.
No model made stuff up. Last time, Gemini fabricated two executives. In this one, nobody invented anyone. That’s progress.
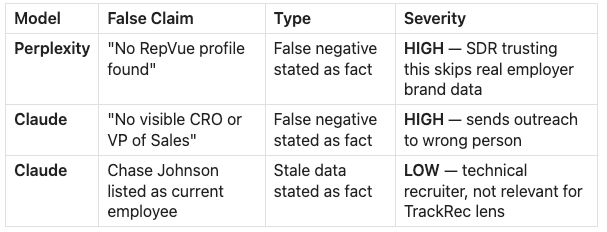
Three false claims
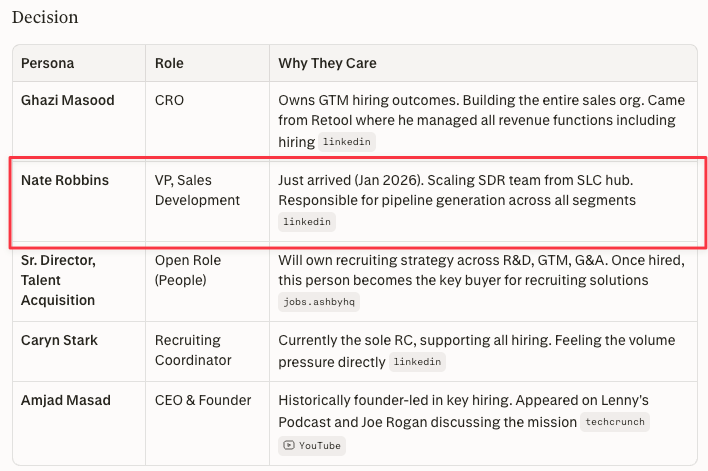
Claude said “no visible CRO.” Here he is. Ghazi Masood, CRO at Replit. Five other models found him.
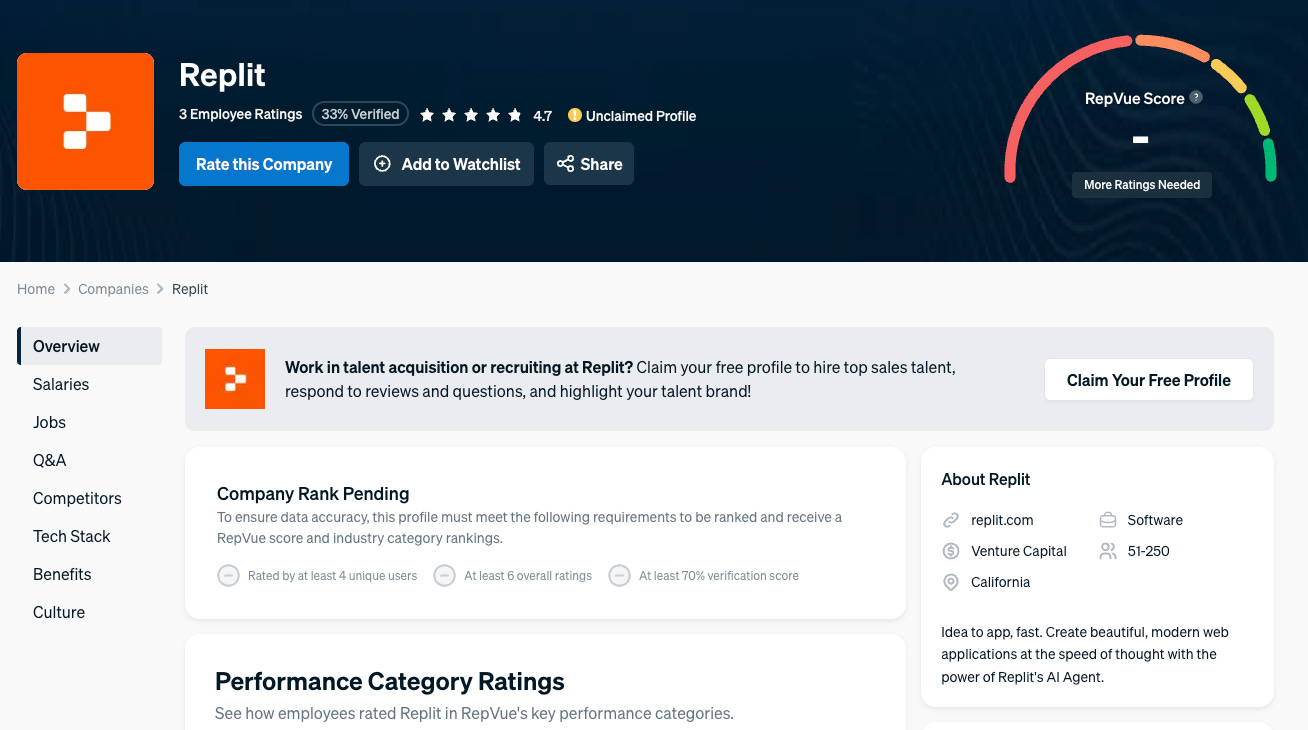
Perplexity said “no RepVue profile.” Here it is. Overall rating 4.7, quota attainment 73%. Four models found it.
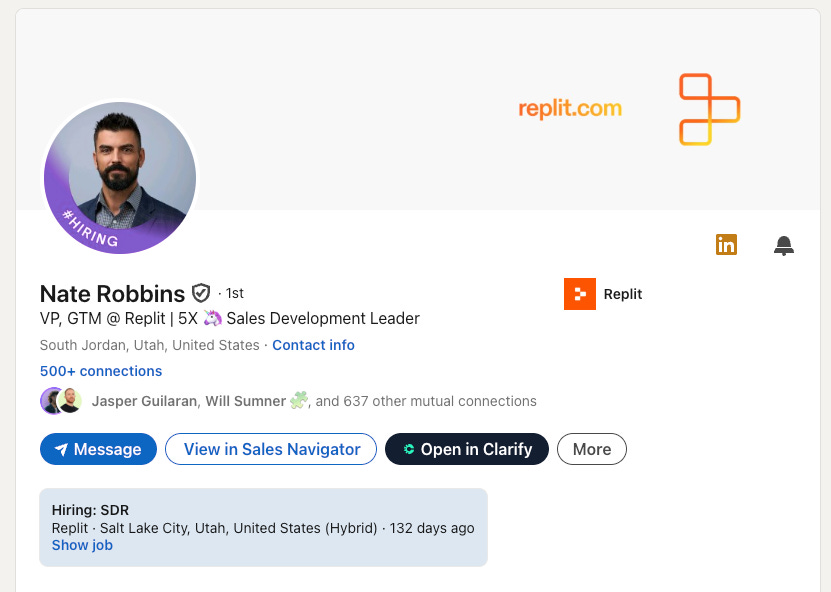
Only Perplexity found him. Nate Robbins, VP of Sales Development at Replit.
REPORTED vs. VERIFIED.
Press says the $400M round happened. Replit’s own website only shows $250M. Should your SDR reference funding the company hasn’t announced? Grok 4.2 hedged — said “follow-on talks.” That might be the most honest answer in the whole test.
Verification Summary
Zero hallucinations. 3 false claims total.
5. How I’d Actually Use These
Perplexity or GPT for the research, and if you want to go 1 layer deeper use Claude to analyse the findings.
If you’re running 500 accounts: GPT is the safest. Zero false claims. You trade depth for safety.
If you’re researching 10 high-value accounts: Perplexity. Spot-check the “not found” answers.
6. Where You Can Actually Use Each Model
Every model was tested in its web app (or Clay for the Argon Model). If you want to run these at scale in Clay or via API, here’s what’s available:
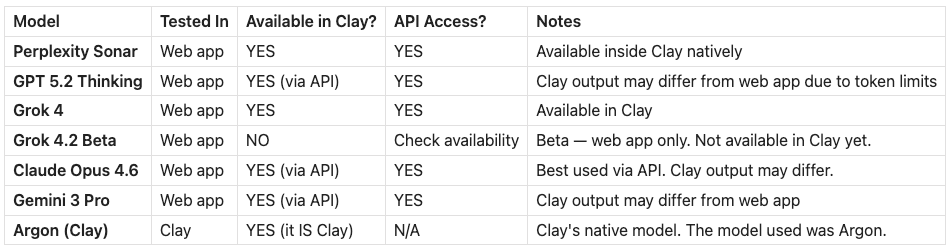
The scores in this test are web app scores. If you run GPT 5.2, Claude, or Gemini through Clay’s native integration, the output might be constrained by Clay’s token budget. Perplexity and Grok 4 are available directly in Clay. Grok 4.2 is beta and web-app only, you can’t use it in Clay yet. Claygent IS Clay’s model (Argon), so that score is exactly what you’d get.
In the next benchmark, I’ll test the models in the web app vs. Clay vs. API to measure the gap.
Here’s the prompt, If you want to get the prompt I used:
P.S. I’m also building a prompt builder for paid members so you can create your own account research prompt customized to your product.
Listen to this episode with a 7-day free trial
Subscribe to Outbound Kitchen to listen to this post and get 7 days of free access to the full post archives.
