

Your outbound stack has one job
Most teams build for the wrong one. Here's how far your team can actually build toward it.

Brought to you by:

Stop running outreach across four different tools
lemlist customers describe it as solving ‘the problem of having to use multiple tools for outreach.’ Email, LinkedIn, and WhatsApp in one workflow. 4.6 on G2 across 1,653 reviews.

Your outbound stack has one job.
Most teams build for a different one: how many tools do we need, should we consolidate, what's the best data provider, etc.
All the wrong questions.
The one job is this:
Get your reps in front of the prospects most likely to convert and stay, armed with the best message to educate them. The highest-fit, highest lifetime value (LTV) accounts, reached with the sharpest message. Every part of the stack serves that. Data and scoring find and rank the right accounts. Your playbook and AI sharpen the message. Automation clears the low-value work so the human hours land where they pay back. The goal is rep time on the right accounts, with the right message, at the right time. The number of tools is only ever an output of that.
That sets up the second decision, the one teams get wrong: how far you can build toward that goal is capped by what you can maintain. Your stack is a resources-to-maintain-complexity decision, and that gate decides every call. Build versus buy. Consolidate versus expand. Whether your next tools make reps faster or just busier.
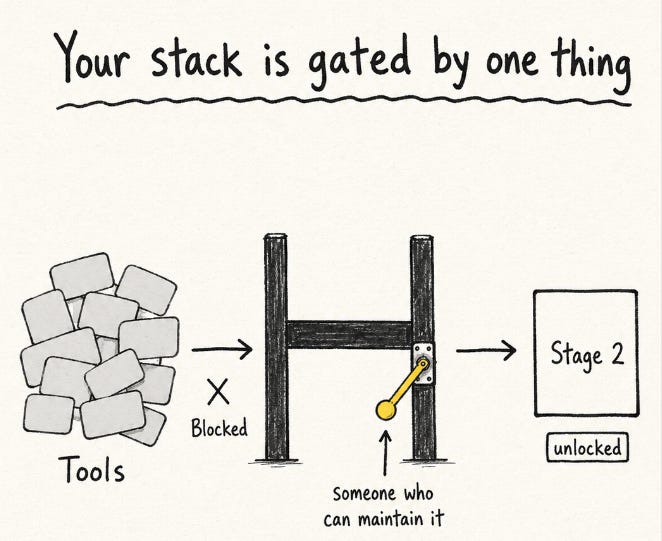
The most expensive mistakes in outbound tooling is stack envy: copying what other teams run or copying a more advanced team runs and inheriting complexity you cannot keep alive.
So the first step is knowing what you can run. Tools come after. An 8-rep team and a 300-SDR org can sit at the same stage, and that gap is the whole point.
We're back with 2 new live sessions
This Thursday I’m going live with Will Rohleder, SDR Director at TeachTown, whose 14-person SDR team wins 42% of the deals they source, against 34% without them.
The week after, Florin Tatulea joins me live (Author of Prospecting from the Trenches & GTM Engineer in Residence at ZoomInfo). We're going to unpack How to Scale an Outbound Team in 2026.
Step 1: Find your stage
Two questions tell you where you are.
Do you have a RevOps or GTM engineer, in-house or fractional WITH bandwidth to support your team?
Do you have a dedicated data team building your data stack?
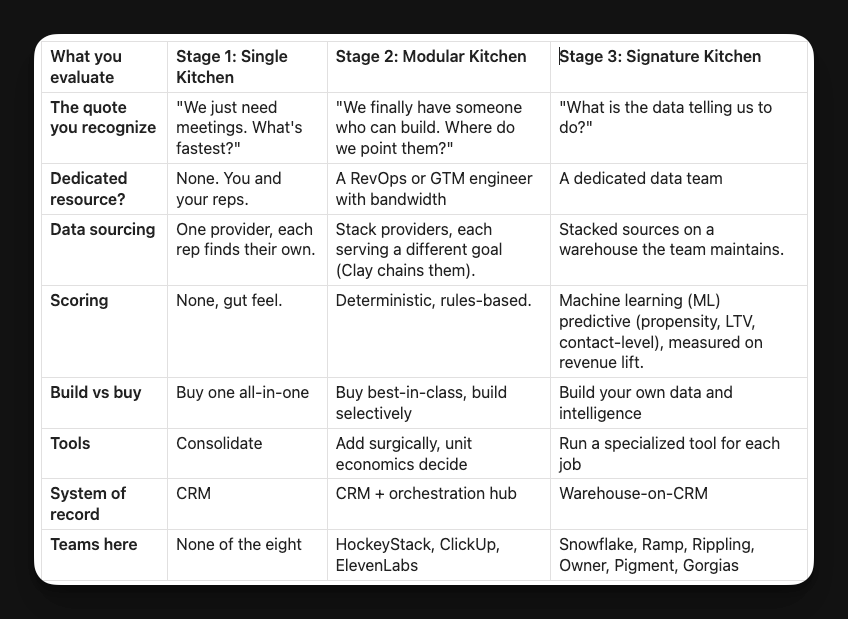
Your answers place you in one of three stages:
Stage 1, the Single Kitchen: no ops, no engineer. You and your reps run everything.
Stage 2, the Modular Kitchen: a RevOps or GTM engineer with bandwidth to build for outbound.
Stage 3, the Signature Kitchen: a dedicated data team building your data stack, your own predictive scoring, the models that decide which accounts and people to prioritize.
These stages stack. Stage 2 is Stage 1 plus someone who can build. Stage 3 is Stage 2 plus a data team on top. You move up by adding the next layer, never by skipping one.
The gate is resources, and resources means bandwidth. A RevOps title with no hours behind it does not move you up. Most teams I know sit between Stage 1 and Stage 2: they have a RevOps person, but that person has no time for outbound. I worked with a company that had one ops person for 50 reps. That person owned the full funnel, from pipeline creation at the top to closing at the bottom to expansion and renewal after the sale. With all of that on their plate, no bandwidth was left for the SDR team’s top of funnel. A request that should take a day took two weeks, sometimes a month. The resource existed, but the time did not, so the team ran like Stage 1. That is the case for a fractional hire or an agency: someone, internal or not, whose only job is the part you actually need. The spread across the best teams I studied proves the gate is resources, not size.
I spent eight months breaking down how the best outbound teams build, from three-rep startups to three-hundred-SDR machines. Look at the two ends of that range. Snowflake runs roughly 300 SDRs. Behind those reps sits a dedicated SDR ops and enablement team plus internal data teams, and every tool earns its place in revenue. Now look at Gorgias. Eight SDRs total, running 5,000+ unique AI emails a day at $0.002 each, off a machine a dedicated team built before the first SDR was hired. By the test that matters, Gorgias sits at the same stage as Snowflake’s 300. If the gate were size, those two could not share a row. They share it because both have a team maintaining the machine.

One more finding, and it matters most if you are early. None of the eight elite teams I studied is Stage 1. Every one had already put someone on the system, a RevOps lead or a GTM engineer, before any of this worked. Stage 1 is a starting point you move through. You leave it by getting someone who can own the system, not by buying another tool.
That confirms the test works. Now build for your own stage.
Here is the full map: what you decide at each stage, and where each team lands. Read it as the center of gravity at each stage, not a checklist. You will not have every row, and that is fine. You will know your row the moment you read the quote in it.
Weigh that resource’s cost against what it unlocks before you add it. Headcount and revenue do not move you up; the person who can run the system does.
Treat your data the way a serious kitchen treats its ingredients, because the dish is only as good as what goes in it. Most teams source data like a diner running on supermarket and frozen food: one cheap provider, nobody checks the quality, and it shows up in every email, call, and forecast downstream. That is Stage 1, and it is the costliest habit on this page, because bad data poisons everything after it. Stage 2 goes farm-to-table: a specific provider for each ingredient, stacked for coverage and quality, sourced for your market. Stage 3 grows its own garden: it builds and scores its own data, so it controls the quality of the ingredient and improves it over time. Run your stack like a Michelin kitchen, where the sourcing is the first thing you obsess over.
Step 2: Forget vendor categories. Every tool does one of six functions
The categories vendors sort themselves into are the wrong mental model. G2 has dozens of them. Your stack has six functions:
Data. Company data, contact data, intent. This is the most market-dependent function in the stack, so build it around your industry. You stack several sources, each serving a different goal: Snowflake runs four intent providers at once, and tools like Clay chain providers to fill the gaps. In many verticals the data your buyers leave online sits outside the big databases, so the right data stack for the trades looks nothing like the one for enterprise IT.
Orchestration. What builds and runs your workflows. The glue.
Execution. The touches themselves. The real design decision lives inside this one: who runs each touch, a human or an automation, by tier and channel. Gorgias automates most of its email. Cold calls stay rep-owned. Same category, two different answers, decided on purpose.
System of record. Your CRM, or your data warehouse once you can maintain one.
Context. Your playbook. The only function with no logo and no line item, and the one that decides whether your AI tools work at all.
AI. The models themselves (OpenAI, Anthropic, and the rest). They run inside the other five, sharpening data, orchestration, execution, and context. AI is the layer you build on across the whole stack.
One axis runs under all of them: frontend is what reps touch, and it stays short. Backend is where mature spend goes. The reason to keep the frontend short is time: every minute a rep is not fighting a tool is a minute on the revenue activity, prospecting for SDRs, selling for AEs. You design the stack to protect that time and let the backend carry the load.
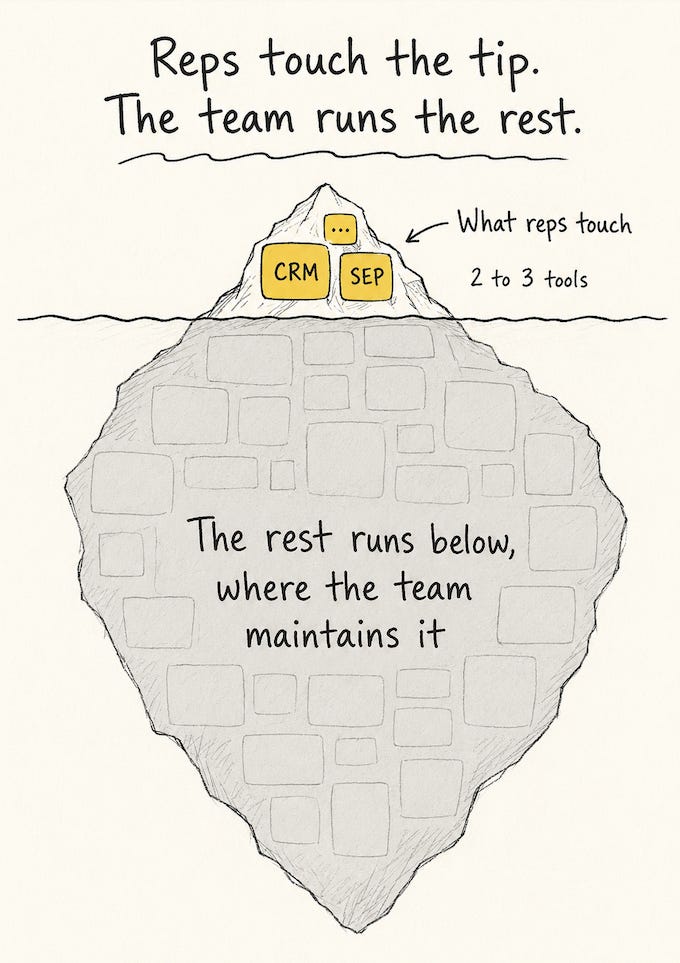
Budget by function, not by vendor category. The rest of this guide gets simpler: each stage is just a different answer to who owns each function.
Step 3: The play for your stage
What you do depends entirely on your stage. Here is the play for each. Run the one that matches where you are now. The plays above your stage will break you: they add complexity you cannot keep alive.
Stage 1: no ops or engineer
Buy one all-in-one platform that sits on top of your CRM and covers contact data plus sequencing, so you are not stitching vendors together. Lemlist, Amplemarket, or Apollo.io on top of your CRM is the honest default here. Pick speed to launch over flexibility you cannot use yet. You can stand this up in days, not weeks, and start learning what works before you spend on anything specialized.
What you skip on purpose: separate data providers, any standalone AI platform, anything that needs an admin to keep it running. One good data source is enough at this stage, and you have no validated data for an AI tool to act on anyway. Data first, AI second. If a line item needs someone to maintain it, it belongs to the stage above you, not to you.
Stage 2: a RevOps or GTM engineer with bandwidth
The trigger hire is what moves you here, and it changes what your stack can be. For the first time, someone can own and maintain complexity that reps never touch. So this is where you stop only buying and start building where it pays.
Go best-in-class, surgically integrated. Keep your CRM and your sales engagement platform (SEP) as the two surface tools reps touch daily, then bolt on the back-end tools that remove real work from a specific workflow. I run lemlist at this stage, and some teams keep it into Stage 3. Outreach or Salesloft are the heavier alternatives. Unit economics decide every add, not logo count. A $150-a-seat enrichment tool that removes 40 percent of non-fit dials stays, no matter how it looks on a tool-count slide.
This is also where AI workflows live, not Stage 3. Your one technical hire plus tools like n8n, Cursor, and the Claude or ChatGPT API can support a back end that used to need three people. When a vendor cannot deliver, you build. I am building an n8n account-research automation for a customer right now because the off-the-shelf output was not good enough for their context. That is the build trigger in practice: a real priority, a vendor limitation, and one technical resource who can own it.
What you skip on purpose: the data warehouse. You will be tempted. Do not, yet. A warehouse has to be maintained, and that takes a data team you do not have. Spend that build energy on AI workflows instead, where one hire can keep it alive.
Stage 3: a dedicated data team
The data team changes what you know, on top of what you can already build. Selective building already started at Stage 2. What is new at Stage 3 is that your decisions run on data: a predictive model scores every account and tells you where reps should spend their hours, so you know what is working, what is not, and what to do next instead of guessing. Three moves open up that were wrong everywhere below.
First, stand up the warehouse-on-CRM backbone. The warehouse stores, enriches, and scores on the back end. That split is only safe because you finally have the people to maintain it and run the models. This backbone is the engine that makes you data-driven.
Second, run a specialized tool for each job. A 24-tool stack is not bloat here, because every layer ties to revenue and you have the team to cut what does not convert. And reps do not touch all 24. They live in two or three tools, the surface, while the rest run on the back end where the team maintains them. Six of the eight elite teams I studied run Stage 3, and no two run it the same way. One leans on signal breadth, another automates first, Rippling scores and stack-ranks its accounts with an in-house data-science model. Same gate, six answers.
Third, build your own edge: build the differentiator and buy the commodity. Building carried over from Stage 2, and the data team lets you build the thing no vendor will, your own data and scoring. Owner’s CRO Kyle Norton weighs five questions before building: how critical is uptime, how much customization it needs, the engineering ROI, whether it is core proprietary intelligence, and whether it gives a real competitive advantage. His rule of thumb: buy infrastructure, build intelligence. That is why Owner buys its dialer and its CRM but builds its own scoring. The most advanced teams go further and build the rep surface itself. Pigment, Ramp, and Vibe each built their own app on top of the stack, so a rep works in one tab, the next action and every account in one place, instead of stitching six vendor screens together. Vibe walked me through theirs on the podcast, shaped around how their reps actually sell. It is the most mature build there is, far more than a workflow, and it is not for everyone. It only pays if you have the engineers to maintain it and you know the edge it buys. The CRM, the warehouse, and the data underneath stay bought. You build the part that is yours.
What you skip on purpose: the urge to consolidate for its own sake. The instinct that kept you lean at Stage 1 turns into a liability here. If a tool ties to revenue and you have the resources to maintain it, it stays. The question flips from “is this too many tools” to “can we still prove each one pays.”
Step 4: The one move you can make at any stage
There is one Stage 3 behavior a Stage 1 team can copy today, at no cost. Document your playbook, what Kevin Dorsey calls “what great looks like.” Start with one doc, somewhere your tools can pull from: your three best-performing sequences, the reason each works, and the objections that sink the others. This is the fifth function, context, the one with no logo and no line item.
Do it because it is the context your AI runs on. An AI workflow is only as good as what you feed it, and an undocumented playbook makes every AI tool you add later blind. The model draws on generic web text and you get generic output. You cannot stand up a warehouse at Stage 1, but you can write your playbook down today. Skip it and you automate a process you cannot even describe.
The decision sits above the tools, and it never changes. Know what each layer of your process needs. Then buy the best tool you can afford for that layer, at your stage. That discipline scales from 3 reps to 300. The tool count changes at every step, but the thinking stays the same. The right number of tools is the number you can maintain, pointed at the one job: your reps in front of the highest-fit accounts, with the best message, as much of their time as you can buy.
Hope you find this helpful!
See you in the next newsletter.
Elric
P.S. Two things.
Building systems like this is what I do with clients right now. If you want help finding where your funnel leaks and fixing one stage with depth, reply and tell me what your motion looks like.
And I’m building something new: a membership to upgrade the paid newsletter: a way to build these systems without me in the room. The frameworks I unpack in breakdowns like this one, plus the workflows to run them inside your own company.
Other resources that might be helpful on the same topic:


